Errata for Data Mining with Rattle and R.
We also include updates to Rattle that differ from the screen shots in the book and suggestions submitted by readers. Please note that recent versions of rattle have migrated to Advanced Graphics by default, and so the plots will differ from those in the book. To revert to the book graphics, deselect Advanced Graphics in the Settings menu (Stephen Simpson).

Page vii, Line -6. Replace "understand verify" with "understand, verify".
Page 7, Section 1.4, Paragraph 1: Replace "Cross Industry Process" with "Cross Industry Standard Process". (Kee Siong Ng)
Page 13, Figure 1.1, Bottom Right-Hand Box: Replace "Shecdule" with "Schedule". (Kim Kuen Tang)
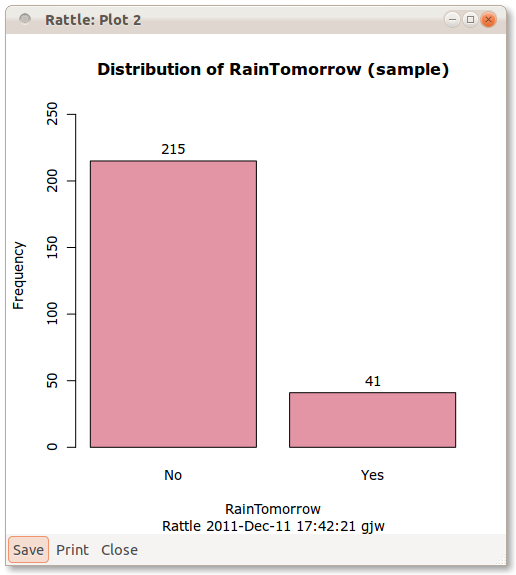
Page 32, Figure 2.6. If we follow the commands from the text we would end up with a different bar plot. The plot in the book results from turning off the Partition check button and hence displays all 366 observations. With the default partitioning, we see 215 and 41 instead of 300 and 66 as in Figure 2.6. Also, for Figure 2.8 it should be noted that RainTomorrow should be reset in the Data tab as the Target variable.
{kind=link}
Page 32, Line 3, and Figure 2.7. The text indicates that MaxTemp has been selected in Figure 2.7, whereas MinTemp has been selected. (Maciej Pilichowski)
Page 53, Line -3. Replace "WE" with "We".
Page 90: The example URL to a Google Ad Planner table has been deprecated. You will get an error failed to load HTTP resource. The concept is correct though. Supply a URL pointing to a table of data and readHTMLTable will download and parse it. (Charlie Kaye)
Page 96, Paragrph 6, Line 1, replace "vain" with "vein" (Mark Poler).
Page 105, Section 5.1.4, Line 3: Replace "Hmisc" with "timeDate" (Viktor Galayda).
Page 107, Paragraph 3, Line 5: Replace "There are NA hundred NA three observations..." with "There are three observations..." (Mike Hogan and Robert Iwatt)
Page 133, Paragraph 3. Replace "...Figure 5.18...there are only 21 missing..." with "...31 missing...". (Kevin Florey)
Page 140, Figure 6.3. This figure is a repeat of Figure 6.2. The correct figure is available here.
{kind=link}
Page 155, Figure 7.2 and Page 160. The book shows "By Group" in the figure and discusses "By Group" while Rattle 2.6.15 and later has replaced "By Group" with "Interval". (Kevin Florey)
Page 157, Figure 7.3. The order of the three last graphs are: recenter using median/MAD, log transform, and rank. The text indicates: rank, log transform and recenter using median/MAD. So, rank and MAD are switched. (Kees Schippers)
Page 163, The R code for Constant Imputation is the same as the R code for Zero/Missing Imputation on page 162. It should use a different constant to 0. (Kees Schippers)
Page 180, R Code Blocks 2 and 3. Replace mean(cluster1) with sapply(cluster1, mean), and similalry for cluster2. (Luis George)
Page 184, the square root of 6 squared plus 3 squared is 6.71, not 6.32. (Kees Schippers)
Page 186, Last Paragraph. "...and only eight of the ten clusters". The table actually shows all 10 clusters. (Kevin Florey)
Page 188, the second code block should have another assignment (Stephen Simpson):
data <- weather
nobs <- nrow(data)
vars <- which(sapply(data, is.numeric))
Page 200, according to the figure, support ranges from 0.1 to 0.7, instead of 0.1 to 0.4. (Kees Schippers)
Page 236, not an erratum per se, but would setting cp to 0.1 not still yield an over trained model in this particular example? Would 0.2 be better? (Kees Schippers)
Page 240, Paragraph 3, Line 5. Replace "loss=loss=" with "loss=".
Pages 251-266. This is not an errata as such, but reinforces the point made in the book about slight variations in numeric calculations when randomness is involved. For example, on Page 251, the book has "OOB estimate of error rate: 14.06%" but for a 32bit system we might see "OOB estimate of error rate: 14.84%" or "OOB estimate of error rate: 14.45%". Similarly the Confusion Matrix in the book includes "Yes 26 15 0.63415" whereas we might see "Yes 28 13 0.68292683" or "Yes 27 14 0.65853659". (Kevin Florey)
Page 255. Replace "the Error button" with "the Errors button". (Kevin Florey)
Page 274. The train.err and train.kap values are no longer reported in later versions of Rattle. (Kevin Florey)
Page 274. Replace "the Error button" with "the Errors button". (Kevin Florey)
Page 294, Paragraph 3. Replace ", and so the size of the training set is not usually an issue" with ". Nonetheless, training time tends to increase significantly with the size of the training dataset, and can be prohibitive on large datasets" (Kee Siong Ng)
Send any that you notice to Graham.Williams@togaware.com.
Copyright © 2006-2023 Togaware Pty Ltd
This site is hosted in the cloud by OpalStack.
Last Modified 2014-09-21 16:58:53 gjw
